XML Copy link to clipboard
Data access Copy link to clipboard
The ANALYZE adapter for XML files provides access to any nodes in the XML Document Object Model. The adapter can also access nodes in HTML files.
Configuration Copy link to clipboard
Open the ANALYZE configuration with the ANALYZE configuration editor, and add a new data access as described in section "Data accesses". Select XML as data access type.
Within the configuration panel, you may specify file patterns consisting of projects, folders or file name patterns which describe the XML files relevant for analysis.
Supported keywords:
- resource – A pattern for an XML (or HTML) file path.
- zipped in – A pattern for an archive file (ZIP, GZIP, TAR) in the workspace.
- as html – Indicates that the resource is an HTML file and thus does not have to be well-formed XML.
- resourceURI – A URI to fetch the XML content.
- validation DTD – Configures whether the content should be validated or not. Validation is enabled by default. Add validation DTD = false to disable the validation.
-
include files – Configures whether the adapter should follow
includetags (see W3C documentation of XML Inclusions ). If this feature is enabled, the namespaces in the XML files have to be well formed. The XML adapter loads the files that are referenced by thehrefattribute ofincludetags in the XML namespace and (internally) replaces each of these tags with the contents of the respective file. It will identify artifacts in these included parts of the document as usual, but this may cause the selection propagation to the internal XML editor not to work properly. File inclusion is disabled by default. Add include files = true to enable inclusion of files.
The configuration may contain several resource definitions. If zipped in is appended to the resource definition, the resource is the path inside the archive file and the pattern following zipped in denotes the archive file in the workspace. The XML adapter supports the ZIP, TAR, and GZIP formats. It also supports the common combination of GZIP-compressed TAR archives. In cases of individual XML files that are compressed with GZIP, the pattern directly after resource is ignored and the file is identified exclusively by the pattern after zipped in.
Namespaces are not available in filter expressions and ignored by default. Qualified node and attribute names have to filtered by ‚local-name()’ constraints.
Please note: ANALYZE does not support selection propagation for HTML files and resources in archive files.
Example:
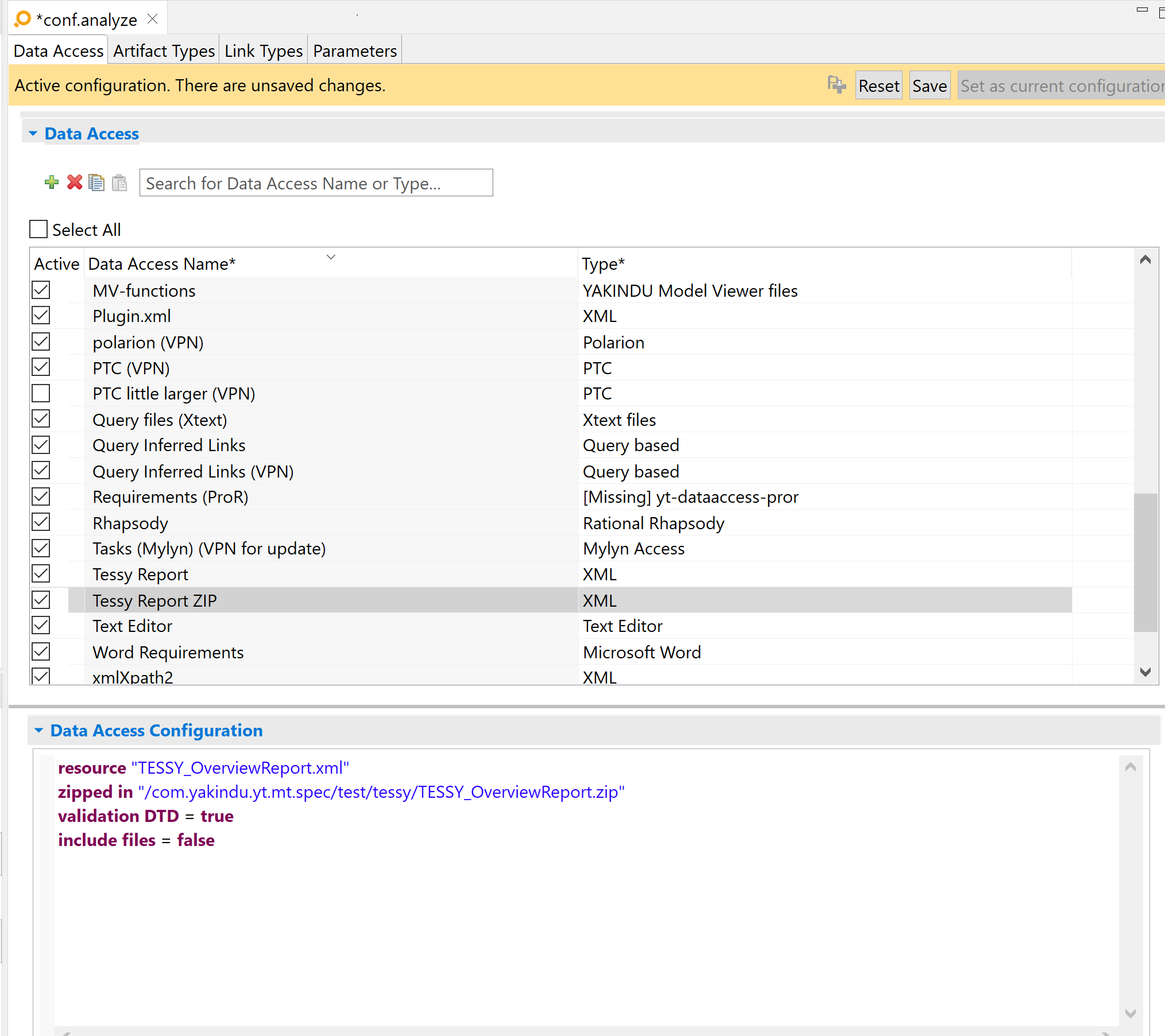
The above configuration tells the adapter to load an XML file from a zip file.
The following configuration explicitly enables validation and disables file inclusion. Since these are the default settings of these options, it has exactly the same meaning as the configuration in the screenshot:
resource "TESSY_OverviewReport.xml"
zipped in "/com.itemis.analyze.mt.spec/test/TESSY_OverviewReport.zip"
validation DTD = true
include files = false
If the example file was an HTML file, the configuration would be:
resource "TESSY_OverviewReport.html"
zipped in "/com.itemis.analyze.mt.spec/test/TESSY_OverviewReport.zip" as html
It is also possible to fetch the XML content via a URI. You see an example for this here:
resourceURI "https://www.example.com/xml/note.xml"
Artifact type Copy link to clipboard
This adapter supports the selection of XML nodes and opening and selecting artifacts within the Eclipse XML Editor, unless the XML file resides in an archive. The XML files have to be defined in the XML data access.
The adapter also supports to identify nodes within HTML documents as artifacts. Internally, each HTML document is converted into an XML document with the same structure. This allows you to select HTML nodes in the same way as XML nodes.
Configuration Copy link to clipboard
Supported options in the configuration:
- artifact source ID where – The unique ID for this artifact source. Multiple element sources can be used in the configuration, allowing to use different element matches conditions or mapping configurations.
- element matches – XPath expression for selecting artifacts
- name – Name for the matched artifact
- identified by – An optional key for an artifact in this document. If specified, it should return a value which uniquely identifies the artifact. If the same value is returned for several XML resp. HTML nodes, ANALYZE will only create one artifact.
- map – Starts a mapping block for specifying custom attributes.
- valueOf – XPath expression
-
joined – Follows a
valueOf(
XPath Expression)
statement and allows to join (concatenate) the elements of a list into a single string, separated by the default separator
,. - joined with separator – Follows a valueOf( XPath Expression) statement and allows to join (concatenate) the elements of a list into a single string, separated by the specified separator.
Example:
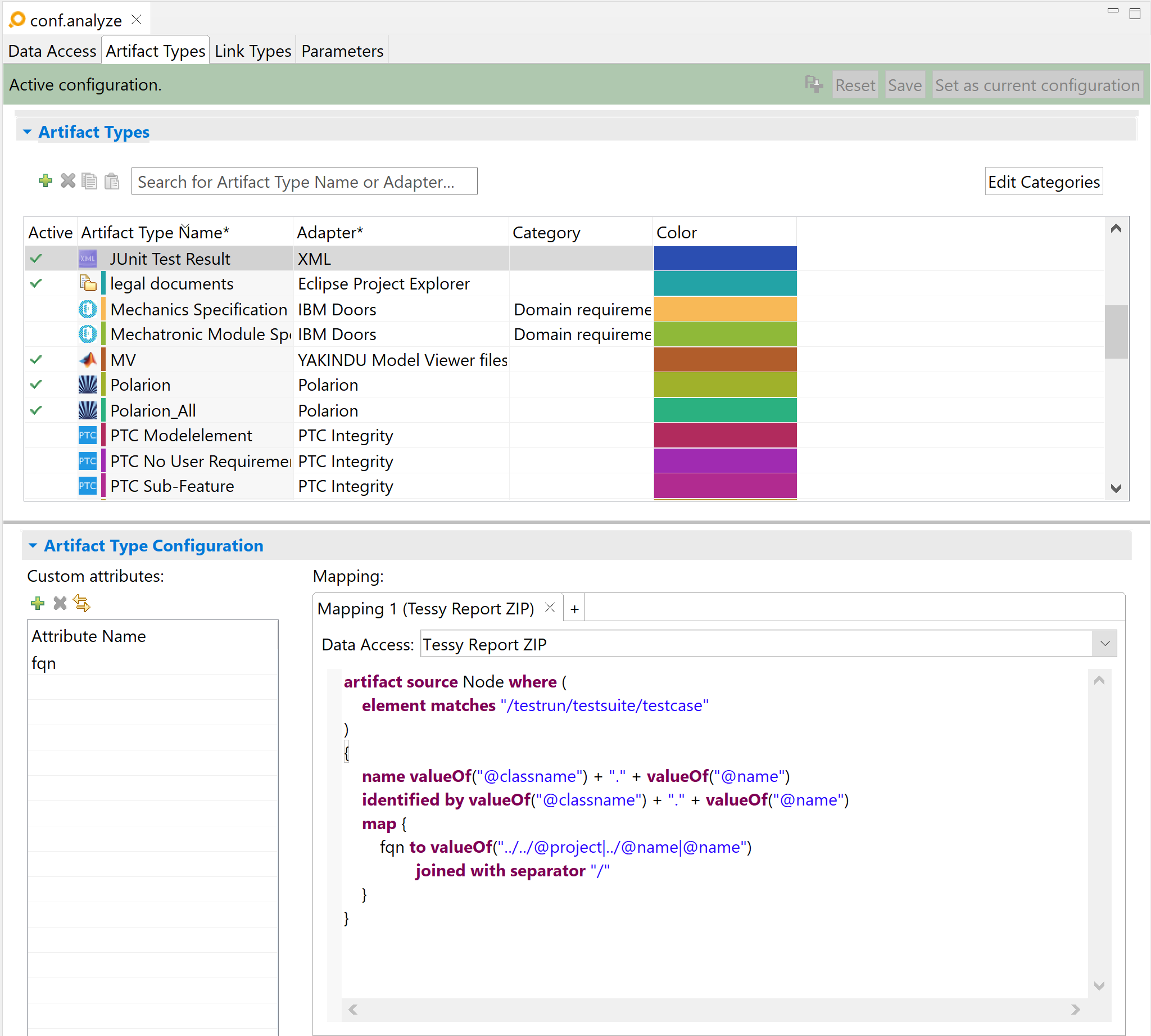
Adapter configuration:
artifact source Node where (
element matches "/testrun/testsuite/testcase"
)
{
name valueOf("@classname") + "." + valueOf("@name")
identified by valueOf("@classname") + "." + valueOf("@name")
map {
fqn to valueOf("../../@project|../@name|@name")
joined with separator "/"
}
}
In the above example, the artifacts will be all XML nodes named testcase contained in the specified path, i.e.:
<testrun> <!-- Root element of the document (/testrun) -->
<testsuite>
<testcase classname="testClassName" name="matchedTestName"/> <!-- Matched artifact -->
</testsuite>
</testrun>
The XPath expressions for name, identified by and mapped attributes will be evaluated against the XML node for each artifact. So, the expression @classname will correspond to the attribute classname of the <testcase> node.
Element matcher Copy link to clipboard
Selectable XML nodes are specified by an XPath expression following the element matches keyword. HTML nodes can be addressed in the same way.
Given the following XML document, the above XPath expression
/testrun/testsuite/testcase will select a single
<testcase> … <testcase>. If the
testcase node had siblings, all of them would be selected.
Sample JUnit result:
<?xml version="1.0" encoding="UTF-8"?><testrun name="EmergencyHandlerTest" project="de.itemis.aad.implementation.java" tests="1" started="1" failures="1" errors="0" ignored="0">
<testsuite name="de.itemis.aad.EmergencyHandlerTest" time="0.001">
<testcase name="testActivateEmergencyState" classname="de.itemis.aad.EmergencyHandlerTest" time="0.001">
<failure>java.lang.AssertionError: Failed as expected!
at org.junit.Assert.fail(Assert.java:88)
at de.itemis.aad.EmergencyHandlerTest.testActivateEmergencyState(EmergencyHandlerTest.java:11)
</failure>
</testcase>
</testsuite>
</testrun>
See XML Path Language (XPath) Version 3.1 for a complete XPath documentation.
Value references Copy link to clipboard
The name and identified by properties from the previous example are expressed as concatenation of value references:
name valueOf("@classname") + "." + valueOf("@name")
The
valueOf keyword introduces a value reference containing an XPath expression. The context of the nested XPath expressions is the matched node from
artifact source. For instance the full XPath expression for
name valueOf("@classname") is
"/testrun/testsuite/testcase/@classname", given that only a single
testcase node is contained in the XML document.
If the evaluation of the XPath expression returns a list of elements, it is possible to concatenate the results of this list to obtain a single string attribute. This is achieved using the joined with separator keyword. For instance:
map {
time to valueOf("//testcase/@time") joined with separator ';'
}
The resulting string will be the concatenation of the time for each testcase contained in the document, separated by semicolon, e.g.,
0.001;0.023;0.358. If the separator is not specified, it defaults to a comma
,.